Abstract
Separating different music instruments playing the same piece is a challenging task since the different audio sources are synchronized and playing in harmony. Moreover, the number of sources may vary for each piece and some of the sources may belong to the same family of instruments, thus sharing timbral characteristics and making the sources more correlated. This paper proposes a source separation method for multiple musical instruments sounding simultaneously and explores how much additional information apart from the audio stream can lift the quality of source separation. We explore conditioning techniques at different levels of a primary source separation network and utilize two extra modalities of data, namely presence or absence of instruments in the mixture, and the corresponding video stream data.
Model Overview
In this work we focus on studying the effect of different types of conditioning and adopt two U-Net versions as the baseline architectures. This is an encoder-decoder architecture which consists of 6 blocks in the encoder and 6 blocks in the decoder. We employ two variants of the architecture, namely: (a) a baseline U-Net architecture as pictured in Figure 1(a) which outputs 13 masks after the last upconvolutional layer, and (b) Multi-Head U-Net (MHU-Net) as pictured in Figure 1(b) which has a single shared encoder and 13 decoders, where each dedicated decoder yields a mask for its corresponding instrument.
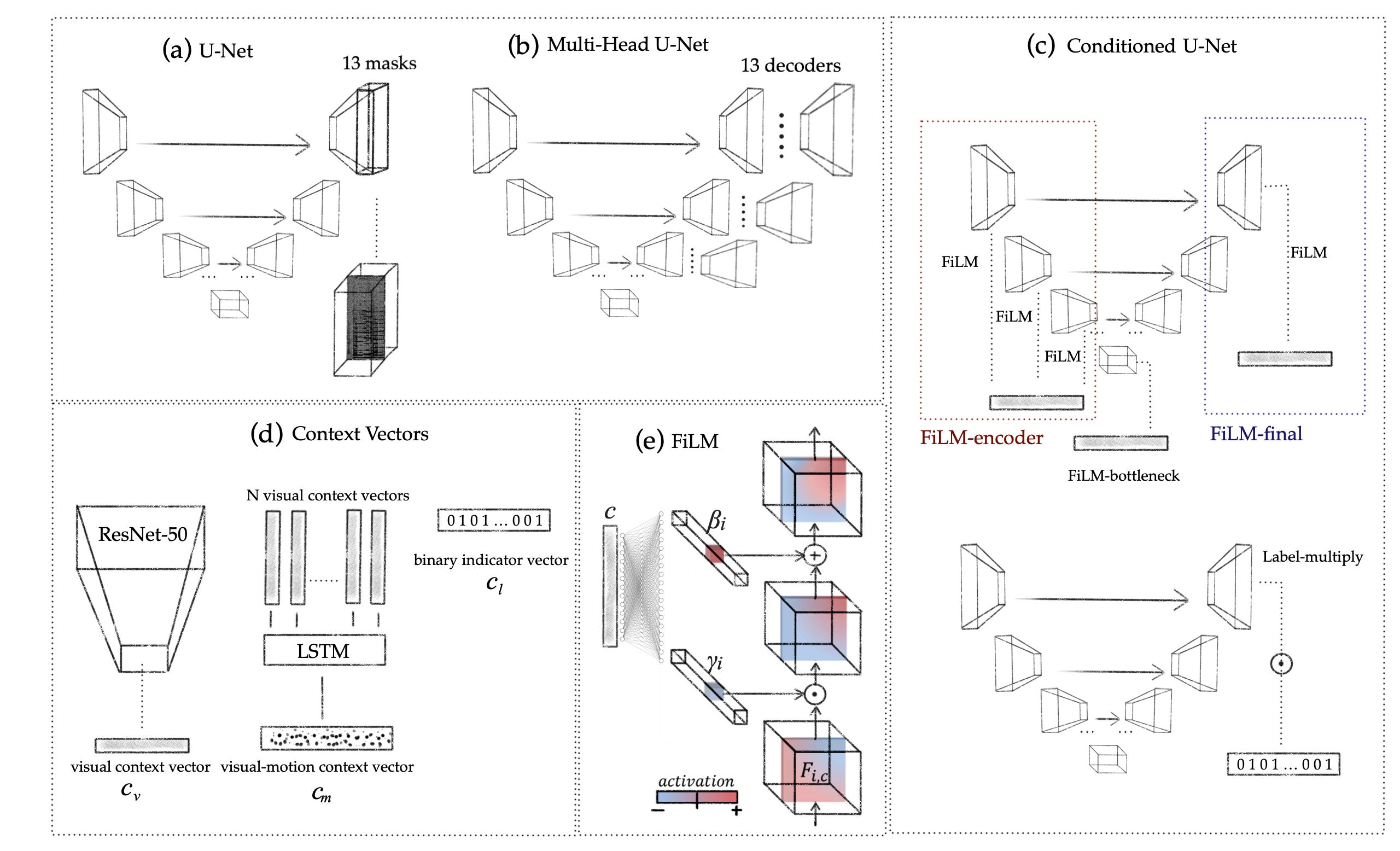
The network takes dB-normalized log-sampled STFT computed over about 6 seconds of audio and outputs binary or ratio masks.
We study label-conditioning and visual conditioning for source separation. For the case of label conditioning, instrument labels are available at the level of individual recordings. They indicate presence or absence of each instrument in the mix, which is encoded in a binary indicator vector $ \textbf{c}_l \in \{0,1\}^{K} $ where $K$ is the total number of instrument classes considered. Then, we use $ \textbf{c}_l $ as a conditioning context vector and compare three types of FiLM conditioning: introduced (1) at the bottleneck, (2) at all encoder layers, and (3) at the final decoder layer as indicated in Figure 1(c). Additionally, we explore simple multiplicative conditioning with the binary indicator vector: \begin{equation} \hat{M}_i = \boldsymbol{c}_{l}[i] {M}_i, \end{equation} where $ \textbf{c}_l[i]$ is the $i^{th}$ component of the context vector and $ {M}_i $ is the $i^{th}$ preliminary mask as predicted by (MH)U-Net.
For visual context conditioning, we take a single video frame corresponding to the beginning of the audio source sample. We use a pretrained ResNet-50 to extract a visual feature vector of size 2048 for every present source, and then concatenate them, obtaining a visual context vector $ \textbf{c}_v $ of size $ K^{\prime} \times 2048 $ where $ K^{\prime} $ is the maximum number of sources in the mixture. The context vector for the unavailable sources is set to all zeros. As for the case of weak label conditioning, we compare three alternatives for the FiLM conditioning (see Figure 1(c)).
Demo
Audio samples
weak conditioning with labels (Exp. 11) in the paper
Trio for 2 Violins and Cello, "Spring" from Four Seasons - Antonio Vivaldi
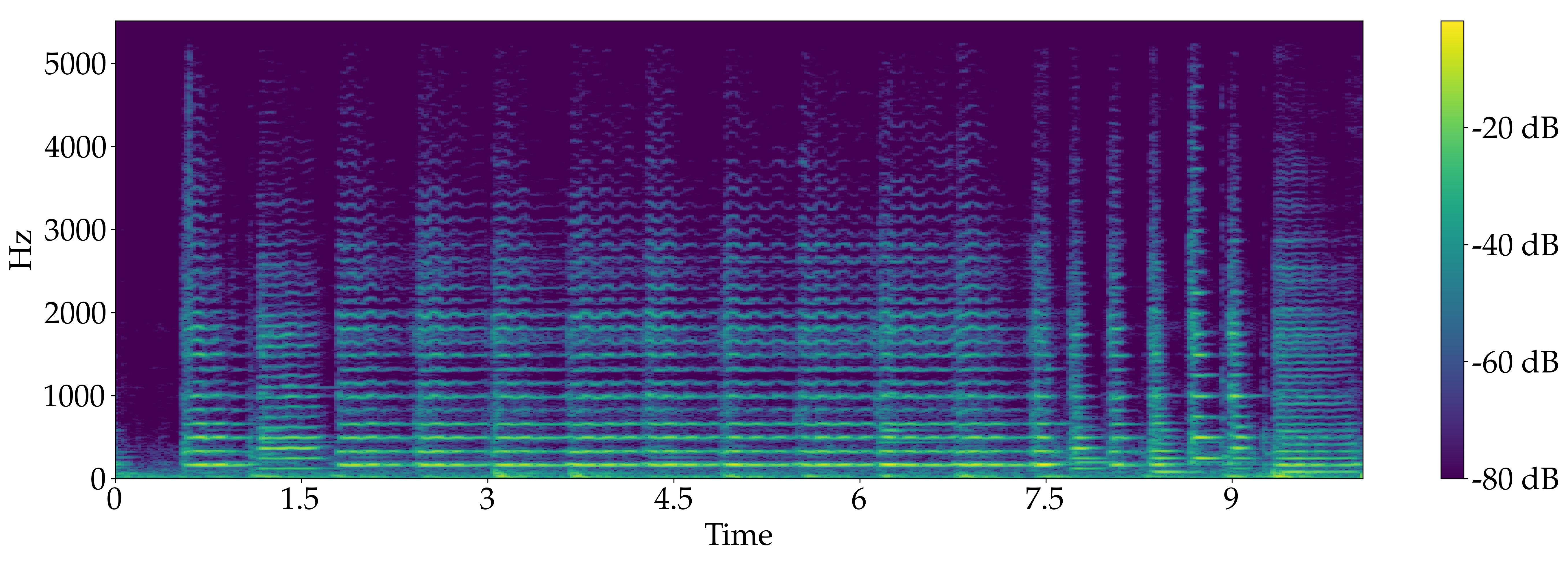
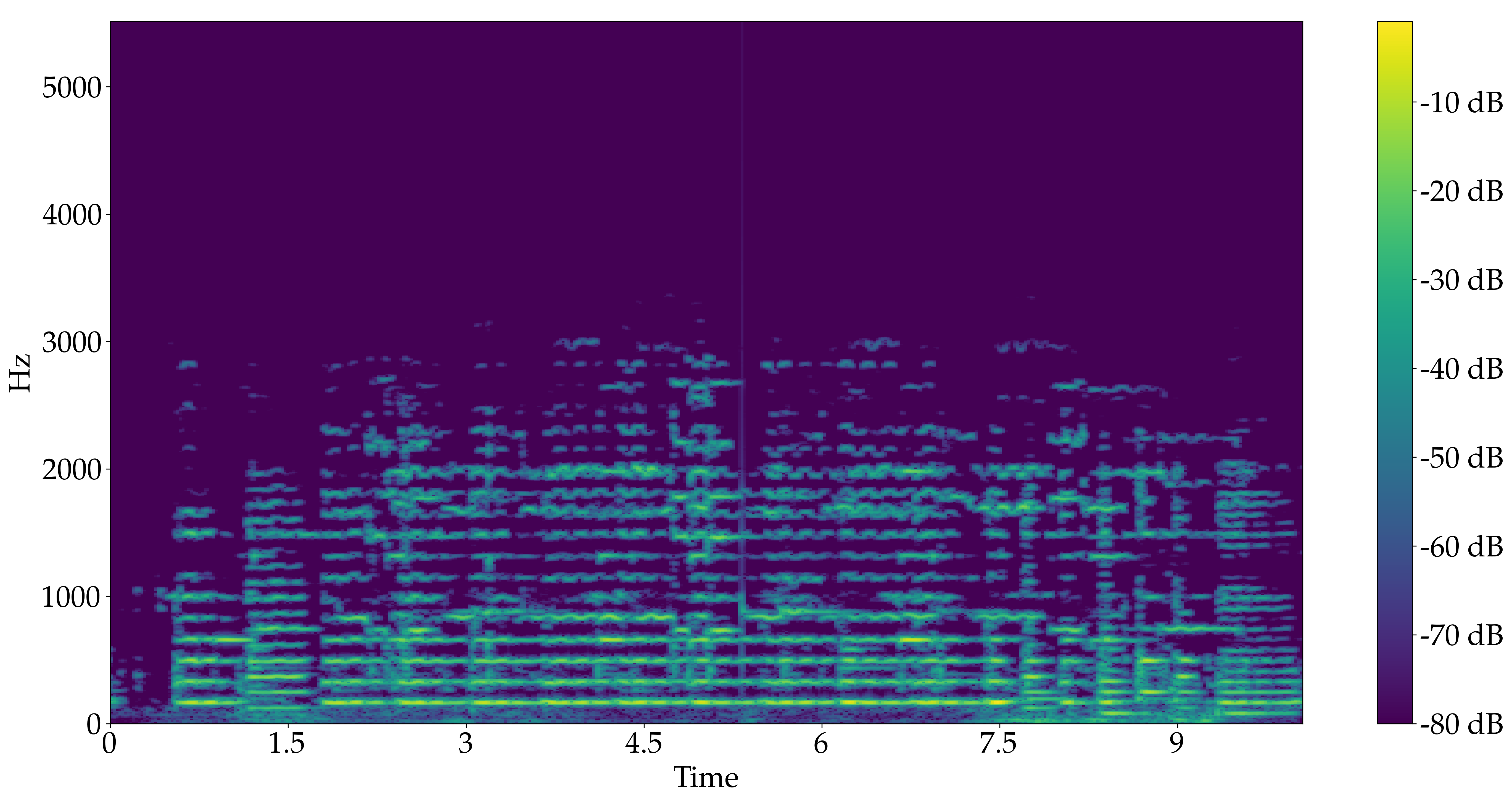
Trio for Trumpet, Violin and Cello, Pavane, op. 50 - Gabriel Fauré
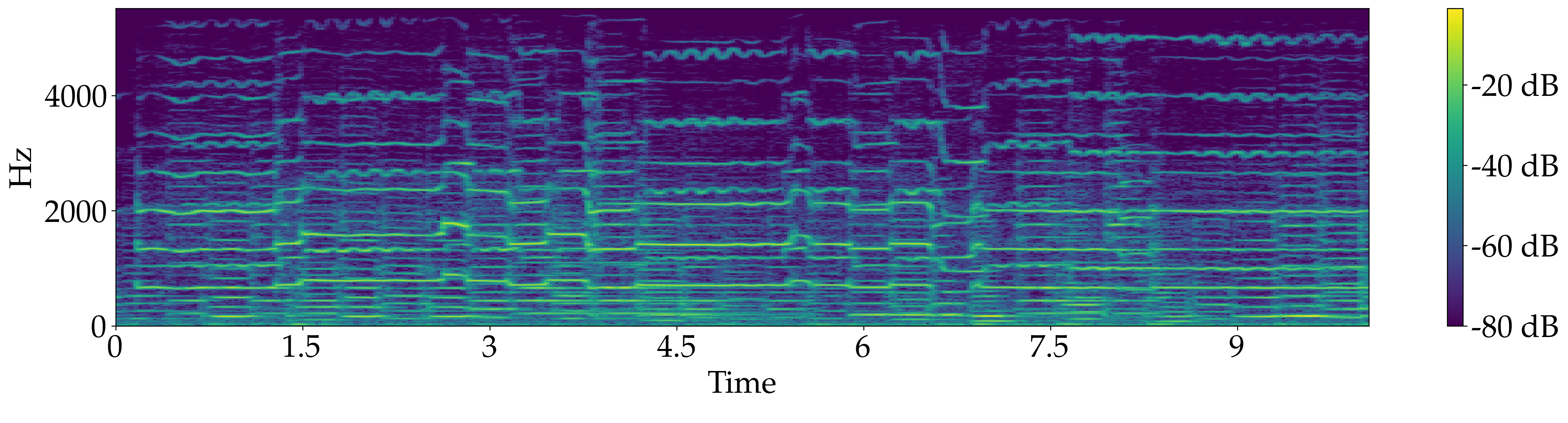
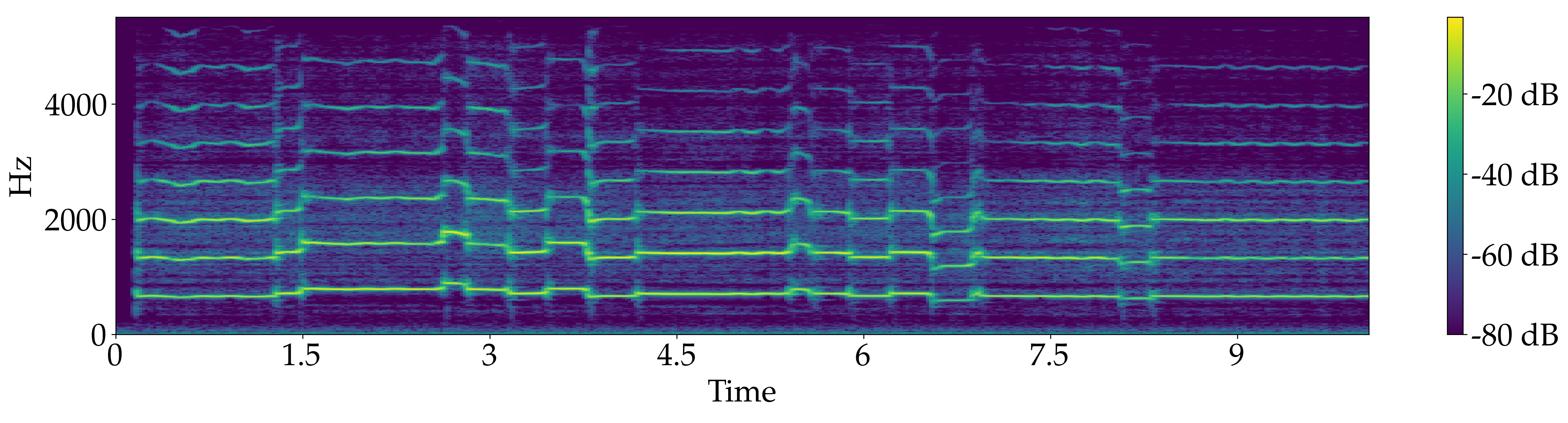

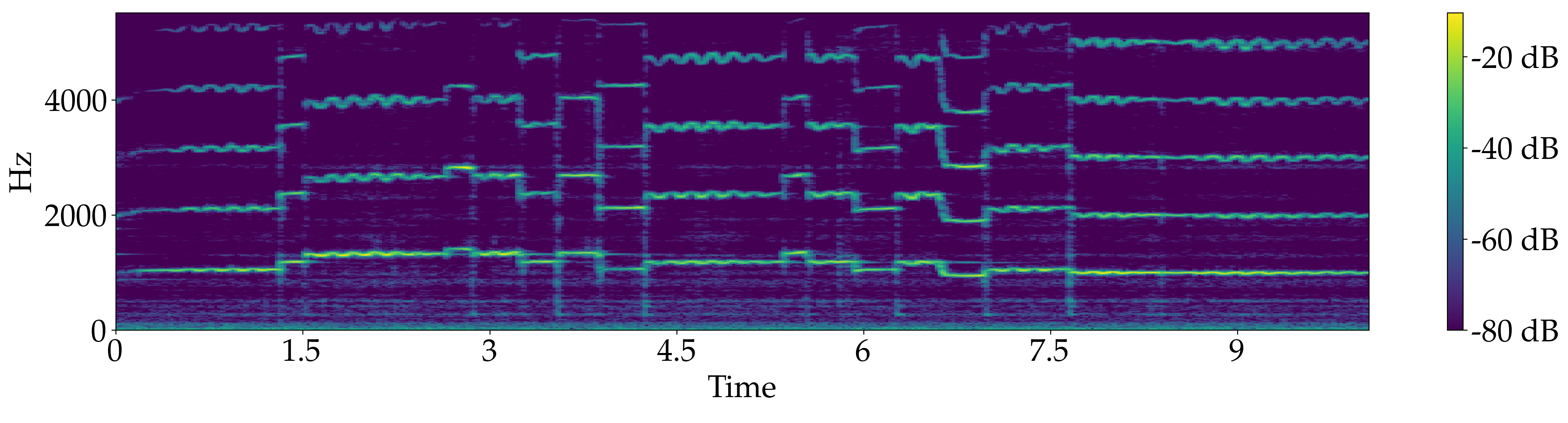
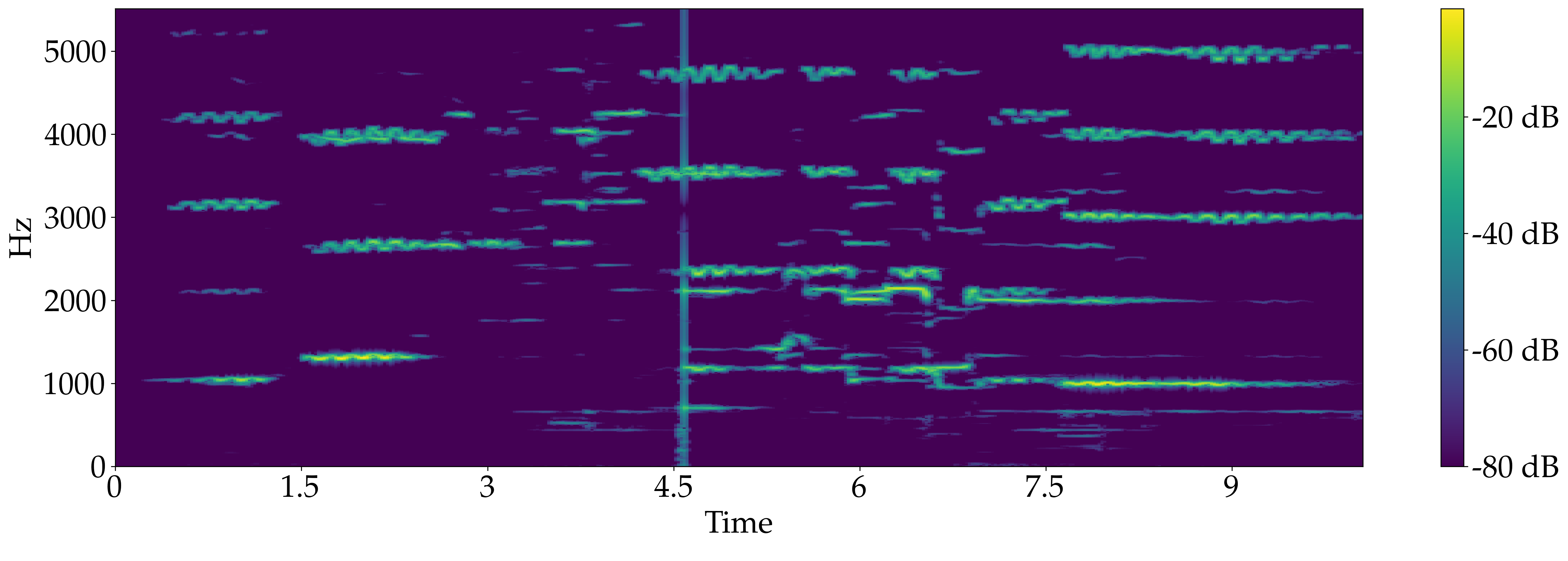
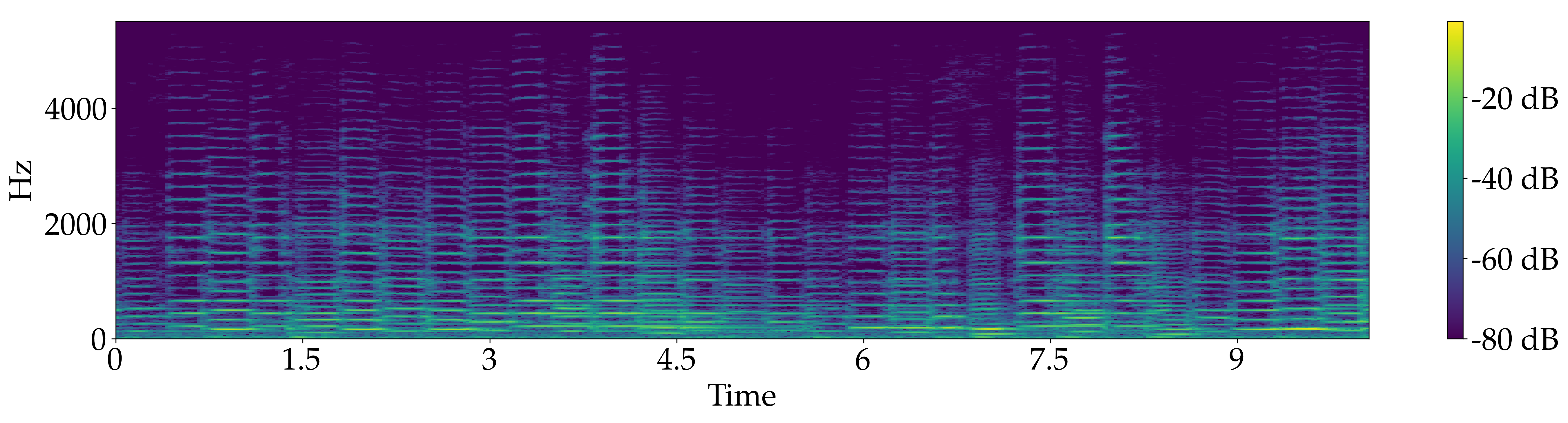
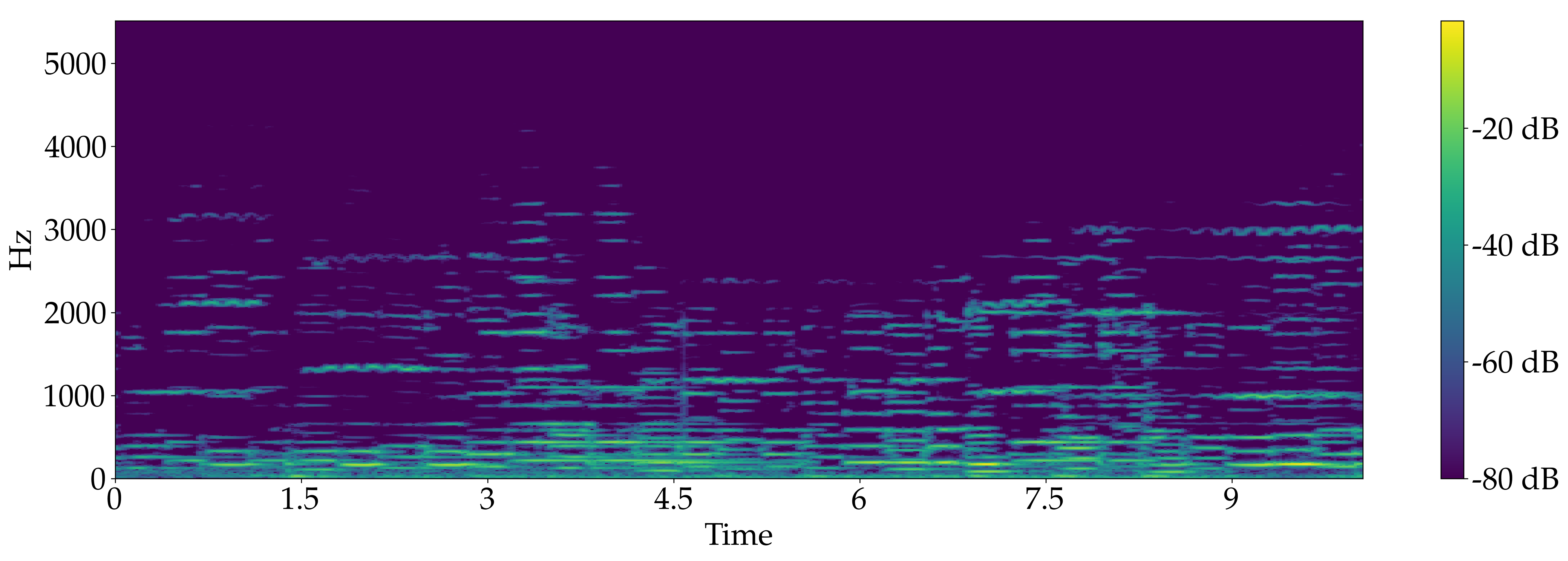
Quartet for 2 Violin, Viola and Double bass, "Rondeau" from Abdelazer - Henry Purcell
Citation
O. Slizovskaia, G. Haro, and E. Gómez. "Conditioned Source Separation for Music Instrument Performances." ArXiv preprint, 2020.
Acknowledgements
This work was funded in part by ERC Innovation Programme (grant 770376, TROMPA); Spanish Ministry of Economy and Competitiveness under the María de Maeztu Units of Excellence Program (MDM-2015-0502) and the Social European Funds; the MICINN/FEDER UE project with reference PGC2018-098625-B-I00; and the H2020-MSCA-RISE-2017 project with reference 777826 NoMADS. We gratefully acknowledge NVIDIA for the donation of GPUs used for the experiments.